Challenges
AI Coach Challenge @ VAR 2026: “Don’t Just Watch. Intervene.”
The workshop will host two challenges on tasks that are crucial to enable real-world vision-based assistants. These challenges are designed to test both the low-level visual capabilities and higher-level reasoning skills of vision-based assistants.
- The winning teams will receive a certificate, a prize and will be invited to present their solution in a contributed talk.
- Deadline: June 1, 2026 (AoE)
Results: Fitness (Winners)
| Team | METEOR↑ | ROUGE-L↑ | BERT↑ | LLM-Acc↑ | T-F-Score↑ |
|---|---|---|---|---|---|
| PKU-FitCoach | 0.296 | 0.194 | 0.891 | 3.556 | 0.652 |
| ISCT_FitCoach | 0.182 | 0.131 | 0.887 | 2.797 | 0.727 |
Results: Cooking (Winners)
| Team | IC-Acc ↑ | Prec. ↑ | Rec. ↑ | F1 ↑ | BERT ↑ | ROUGE-L ↑ |
|---|---|---|---|---|---|---|
| MR-CAS | 56.2 | 0.42 | 0.24 | 0.31 | 0.564 | 0.477 |
| Yeeun Choi | 31.4 | 0.17 | 0.25 | 0.20 | 0.450 | 0.336 |
Results: Fitness Method Highlights
PKU-FitCoach (Peking University)
Members: Minghang Zheng, Jingli Wei, Yuxin Peng, Yang Liu
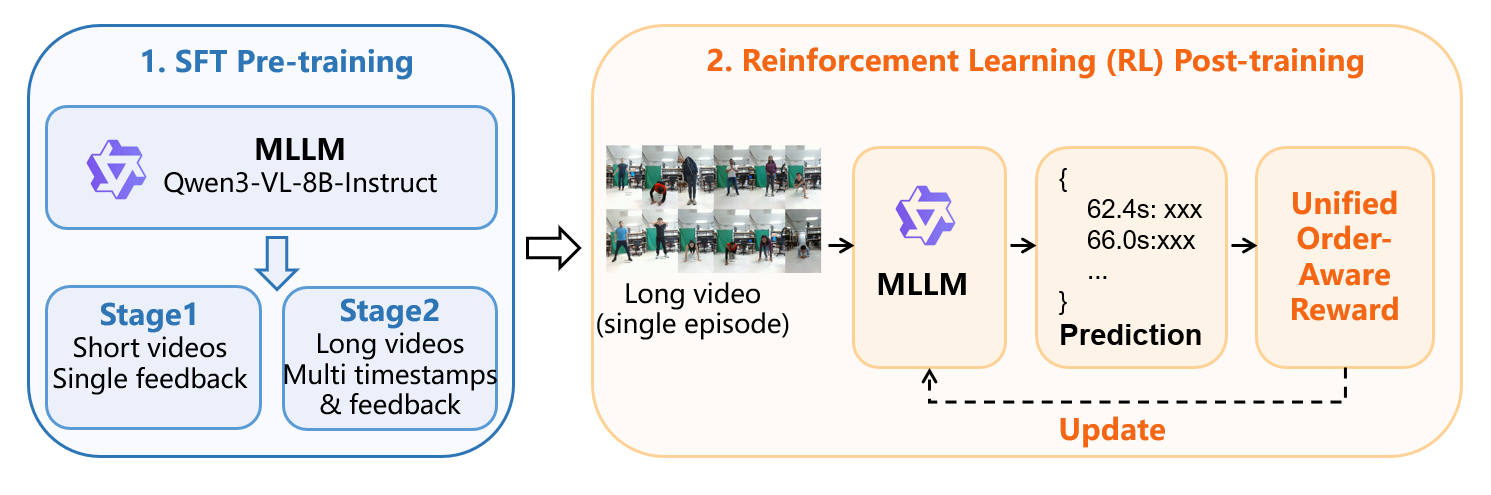
Method: We propose a two-stage framework that combines Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) for timestamped coaching feedback generation from exercise videos. First, a multimodal large language model is trained through a progressive SFT strategy on both short-video single-feedback data and long-video multi-feedback data. Then, RL post-training further improves coaching decision-making with a novel Unified Order-Aware Reward, which jointly models temporal alignment, semantic similarity, and feedback ordering through dynamic programming-based matching. This design enables the model to learn not only what feedback to provide and when to provide it, but also how to organize feedback in a natural coaching sequence, leading to state-of-the-art performance in the AI Coach Challenge.
ISCT_FitCoach (Institute of Science Tokyo)
Members: Koki Kawamura, Shuhei Kurita, Taiki Miyanishi, Inoue Nakamasa
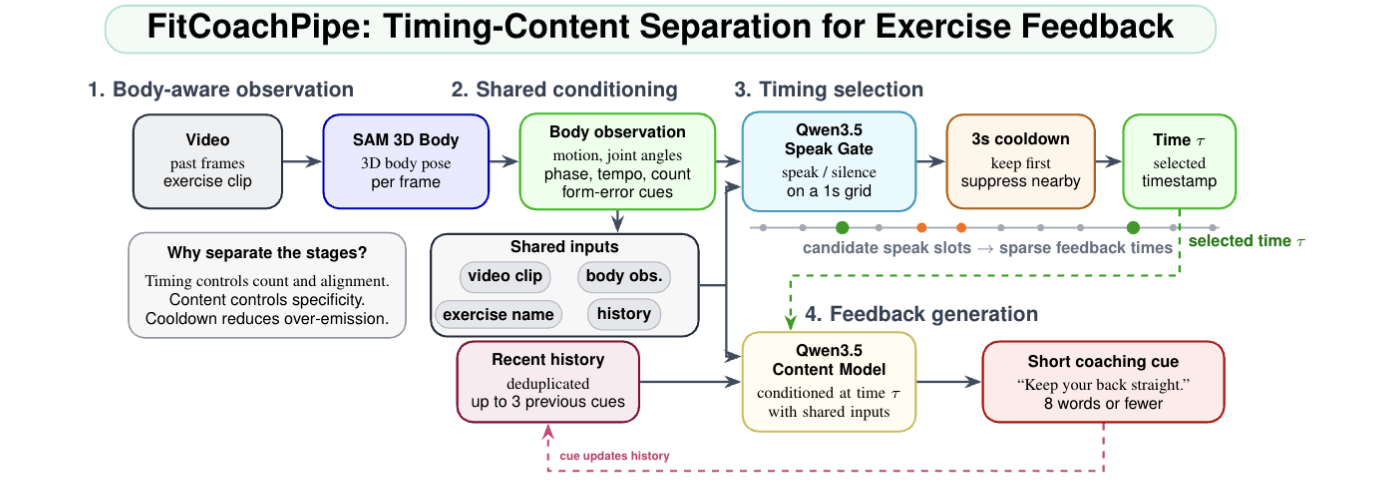
Method: FitCoachPipe addresses the AI Coach Challenge: Fitness by separating two decisions that are often entangled in video-to-feedback systems: when a coach should speak and what concise advice they should give. The method extracts body-aware observations from 3D pose, uses a supervised Qwen3.5 speak gate with a 3-second cooldown to select sparse feedback moments, and then generates short coaching cues with a supervised-finetuned Qwen3.5 vision-language model conditioned on pose observations, recent utterance history, exercise context, and past visual frames. This timing/content pipeline achieved T-F 0.586 and LLM-Acc 3.093 on the local benchmark, and T-F 0.727 with LLM-Acc 2.809 in the official competition evaluation.
Results: Cooking Method Highlights
MR-CAS (Chinese Academy of Sciences, Beijing Academy of Artificial Intelligence)
Members: Ruochen Cui, Yuhai Li, Shilong Bao, Boyu Han, Qianqian Xu, Qingming Huang
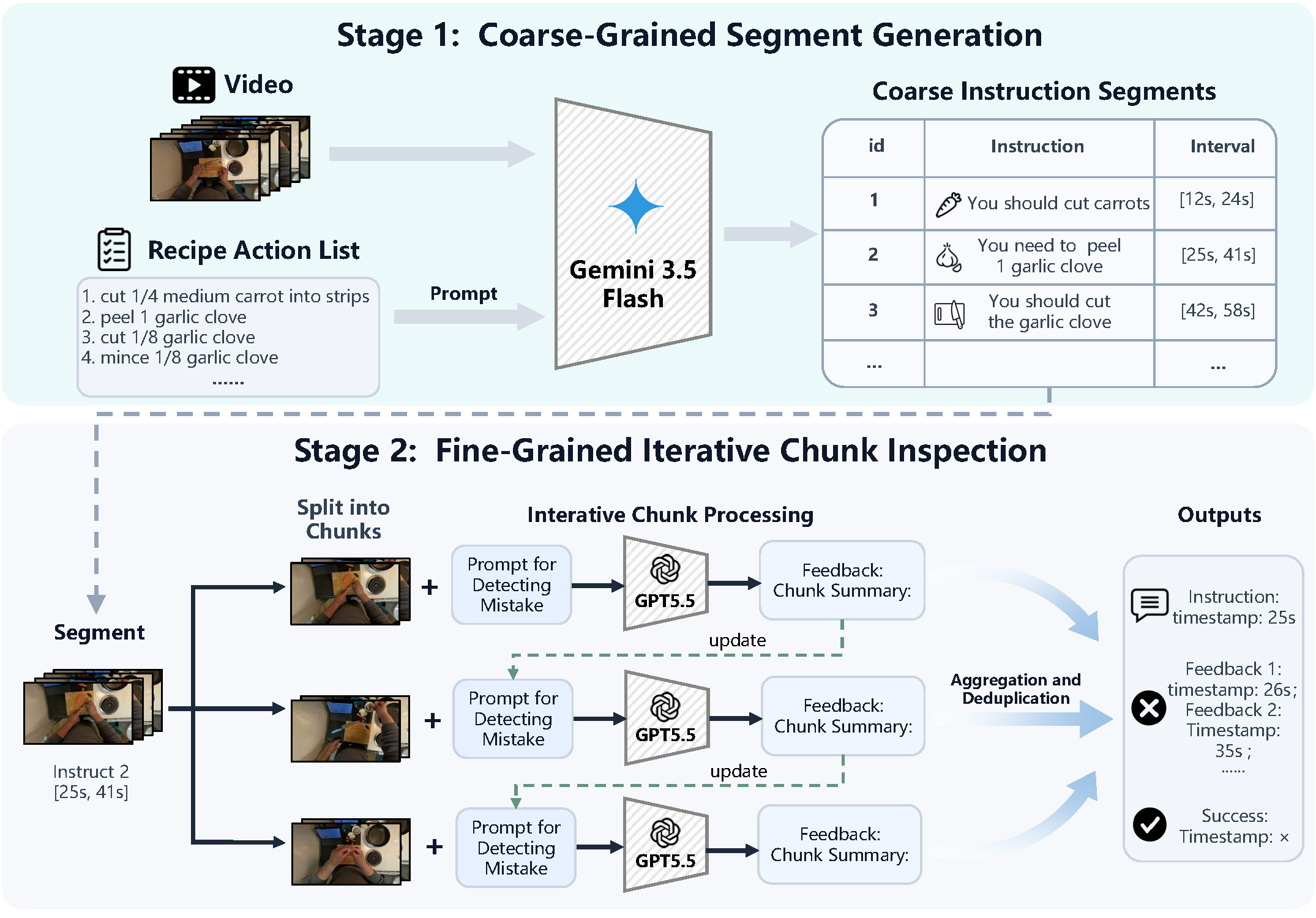
Method: We propose a hierarchical two-stage video understanding framework for the Cooking task in the VAR 2026 AI Coach Challenge. Our method first uses Gemini-3.5 Flash to perform coarse-grained reasoning over the full cooking video and recipe action list, segmenting the video into approximate recipe steps and generating step-level instructions. It then applies GPT-5.5 for fine-grained inspection within each segment to detect visible mistakes, localize their timestamps, and generate corrective feedback. To handle long videos, segments are processed with adaptive frame sampling and overlapping chunks, while summaries of previous chunks preserve temporal continuity. Candidate feedback is merged and deduplicated, and if no mistake is detected, the system produces positive completion feedback. The final output organizes instructions, corrective feedback, and success messages with fine-grained timestamps in the required submission format.
Yeeun Choi (Yonsei University)
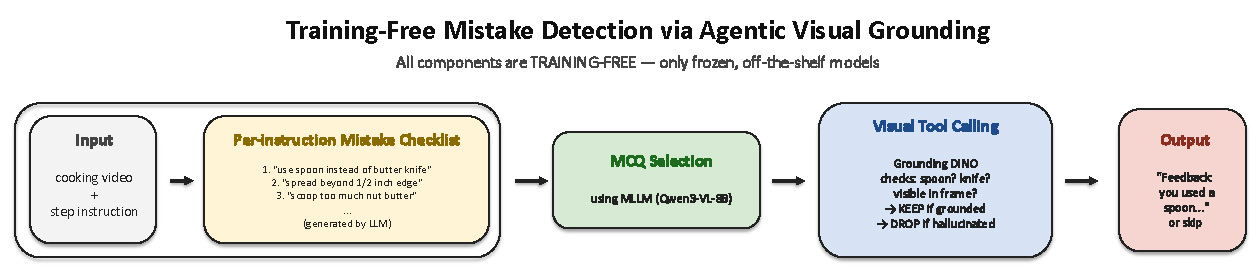
We present a training-free pipeline for the AI Coach Cooking Challenge, built upon the Qwen3-VL-8B-Instruct baseline. In its default free-form setting, this baseline suffers from a strong “no mistake” bias, completely failing to detect errors (F1 = 0.00). Our framework overcomes this limitation to address fine-grained cooking recipes and mistakes without requiring any model fine-tuning. First, following Bhattacharyya et al. (NeurIPS 2025), we generate a checklist of plausible mistakes for each instruction. We then provide the model with the video frames and this checklist, formulating the error-detection task as a multiple-choice selection. Subsequently, we employ an agentic visual verifier (Grounding DINO) via tool-calling to post-check details whether the object nouns referenced in the selected mistakes are actually visible in the frame; predictions lacking visual support are dropped. This verification step significantly reduces false positives. On the official main/test split, our system achieves an F1 score of 0.20 and an IC-Acc of 31.4. This represents a substantial improvement over the 8B baseline (F1 = 0.00, IC-Acc = 19.8), all accomplished with zero training on a single GPU.
Challenge 1: Fitness
Continuing from CVPR 2025, this challenge focuses on coaching users through a workout session with the right feedback at the right time, to correct mistakes and encourage the user. Details:
-
Evaluation Data: We base this challenge on the QEVD dataset, as described here. Specifically, the challenge involves providing timed feedback for a set of evaluation videos. For this challenge, we employ a (private) test set available here.
-
Training and Validation Data: For training and validation, please use the data provided in the QEVD page.
-
Quick Start: We provide a quick start guide that implements a Qwen3-VL baseline that is available here.
-
Evaluation Metrics: We will use the METEOR, ROUGE-L, BERT, LLM-Acc., and T-F-Score as described here. The code for these metrics is available here. If you have any questions contact us here.
-
Participation:
- Leaderboard: Please email the results here as a json file along with the team name. The json file should contain a list of python dicts with the the following fields:
[{“mini_episode_id”: <str: name of the evaluation video file>, “pred_feedbacks”: <List[str]: list of predicted feedbacks>, “pred_feedback_timestamps”: <List[float]: list of timestamps corresponding to the predicted feedbacks>}, ...]See the quick start guide for more details. Each team will be allowed to make five submissions and we will provide the evaluation results of each submission as soon as possible (within 24 hours). The team can choose the make the result public on the leaderboard below at any time.
-
Extended Abstract: The teams submitting to the challenge are also encouraged to submit an extended abstract through CMT. The page limit is a minimum of two pages and a maximum of four pages, excluding references. As subject area please choose “Challenge: Fitness”.
- Winner: The winning team will be decided based on the five evaluation metrics described above. The winning team is the one that outperforms others on most metrics. The code of the winning team will be inspected before the workshop.
- Leaderboard: Please email the results here as a json file along with the team name. The json file should contain a list of python dicts with the the following fields:
Results: Prior Works
| Method | METEOR↑ | ROUGE-L↑ | BERT↑ | LLM-Acc↑ | T-F-Score↑ |
|---|---|---|---|---|---|
| VideoChat2 | 0.104 | 0.048 | 0.846 | 2.145 | 0.555 |
| VideoLLaMA3-7B | 0.150 | 0.076 | 0.859 | 2.554 | 0.555 |
| Qwen-2-VL-Instruct | 0.185 | 0.089 | 0.861 | 2.851 | 0.555 |
| Qwen-2.5-VL-Instruct | 0.174 | 0.068 | 0.855 | 3.153 | 0.555 |
| CVPR 2025 Best | 0.156 | 0.101 | 0.861 | 2.087 | 0.535 |
Challenge 2: Cooking
This challenge focuses on coaching users through a recipe with the right feedback at the right time, to correct mistakes. Details:
-
Evaluation Data: We base this challenge on the Qualcomm Interactive Cooking Dataset (built on top of CaptainCook4D), as described here and here. Specifically, the challenge involves providing timed feedback for a set of evaluation videos. For this challenge, we employ the test set available in the link provided above.
-
Evaluation Set: We will use the main set of the Qualcomm Interactive Cooking Dataset and consider the turn based evaluation scheme described in Section 5.4 here.
-
Training and Validation Data: For training and validation, please use the data provided in the Qualcomm Interactive Cooking Dataset page.
-
Quick Start: We provide a quick start guide that implements a Qwen3-VL baseline that is available here.
-
Evaluation Metrics: We will use the IC-Acc and Mistake (Precision, Recall and F1) metrics as described here. The code for these metrics is available here. If you have any questions contact us here.
-
Participation:
- Leaderboard: Please email the results here as a json file along with the team name. The json file should contain a list of python dicts with the the following fields:
[{“video_id”: <str: name of the evaluation video file>, “pred_texts”: <List[str]: list of predicted instructions and feedbacks>, “pred_timestamps”: <List[float]: list of timestamps corresponding to the predicted instructions and feedbacks>}, ...]The team can choose the make the result public on the leaderboard below at any time.
-
Extended Abstract: The teams submitting to the challenge are also encouraged to submit an extended abstract through CMT. The page limit is a minimum of two pages and a maximum of four pages, excluding references. As subject area please choose “Challenge: Cooking”.
- Winner: The winning team will be decided based on the (mistake) F1 and IC-Acc scores. We will first sort by (mistake) F1 and then IC-Acc scores. If two teams have the same F1 and IC-Acc scores then we will break ties by sorting by BERT and then ROUGE-L scores.
- Leaderboard: Please email the results here as a json file along with the team name. The json file should contain a list of python dicts with the the following fields:
Results: Prior Works
| Method | IC-Acc ↑ | Prec. ↑ | Rec. ↑ | F1 ↑ | BERT ↑ | ROUGE-L ↑ |
|---|---|---|---|---|---|---|
| Videollm-online | 0.03 | 0.02 | 0.98 | 0.04 | 0.332 | 0.248 |
| Qwen2-VL-7B | 6.3 | 0.02 | 0.69 | 0.05 | 0.377 | 0.256 |
| Qwen2.5-VL-7B | 18.9 | 0.18 | 0.01 | 0.02 | 0.299 | 0.219 |
| Gemini-2.5-Flash | 23.1 | 0.01 | 0.22 | 0.02 | 0.410 | 0.342 |